Ollama
Ollama est un logiciel open source permettant d'exécuter des modèles IA populaires tels que Llama 3.2 ou Gemma 2.
Ce guide vous explique étape par étape comment installer et configurer Ollama pour ONLYOFFICE Docs.
Configuration requise
La configuration matérielle requise pour Ollama dépend de la taille du modèle que vous souhaitez exécuter :
| Taille du modèle | RAM |
| 7B | 8 Go |
| 13B | 16 Go |
| 70B | 64 Go |
Au moins 4 Go d'espace disque sont nécessaires pour le binaire Ollama. Un espace supplémentaire est requis pour le stockage des modèles, qui peut varier de plusieurs Go à plusieurs centaines de Go selon le modèle.
Un GPU dédié est recommandé pour des performances satisfaisantes. L'exécution sur processeur uniquement est possible, mais entraîne des temps de réponse nettement plus lents.
Connecter et configurer Ollama
-
(Facultatif) Installez Homebrew si vous préférez cette méthode pour gérer les paquets sous macOS et Linux :
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)" -
Pour installer Ollama, exécutez la commande suivante :
curl -fsSL https://ollama.com/install.sh | shPour une installation via Homebrew, exécutez :
brew install ollamaUne fois installé, Ollama met à disposition des commandes pour servir, lister, inspecter et exécuter des modèles sur votre machine.
-
Suivez les étapes ci-dessous pour configurer Ollama :
-
Lancez le serveur IA local en exécutant la commande suivante dans le Terminal :
export OLLAMA_ORIGINS=http://*,https://*,onlyoffice://* -
Démarrez Ollama immédiatement et configurez son démarrage automatique à la connexion :
brew services start ollama -
Si un service en arrière-plan n'est pas nécessaire, exécutez plutôt la commande suivante :
ollama serve
-
Lancez le serveur IA local en exécutant la commande suivante dans le Terminal :
-
Téléchargez le modèle que vous souhaitez utiliser dans une autre fenêtre de Terminal. Par exemple, pour installer et exécuter Llama 3.2 :
ollama run llama3.2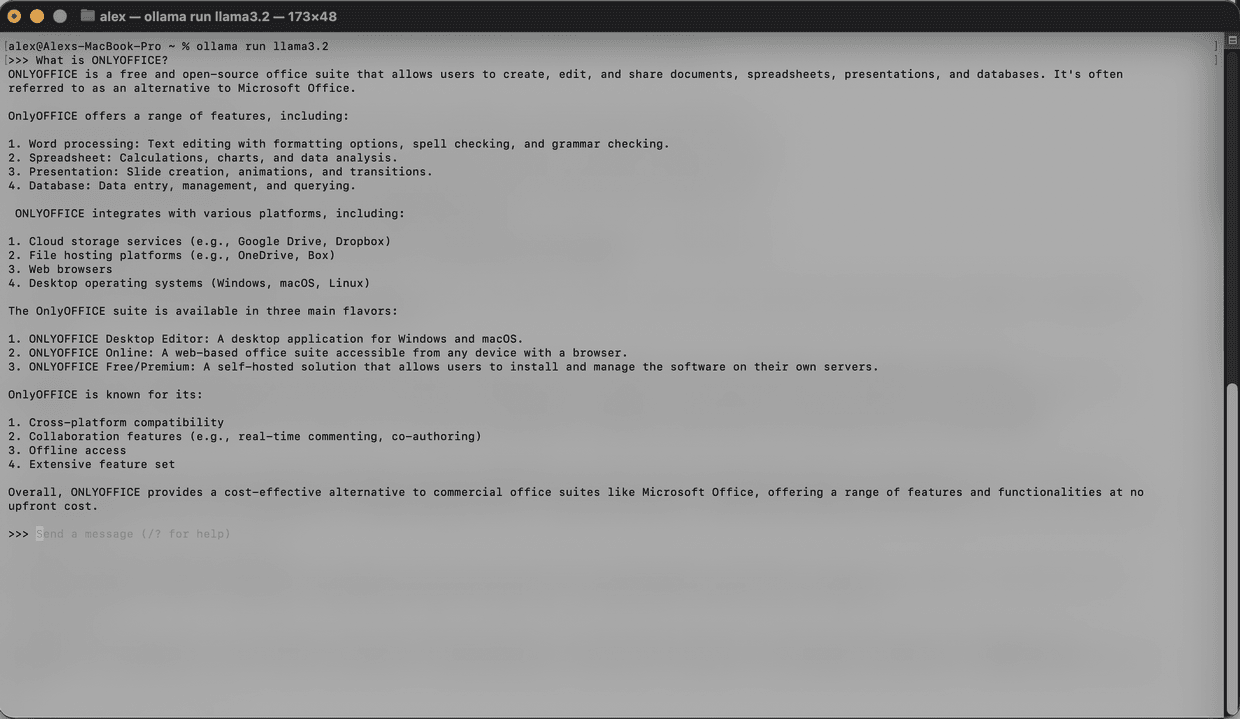
Le modèle sera téléchargé et démarré en local. Le nombre de modèles installés est illimité. Pour la liste des modèles disponibles, consultez la documentation officielle d'Ollama.
Avant l'installation, vérifiez que votre machine dispose de suffisamment de mémoire et d'espace disque pour héberger les modèles..
- Suivez ce guide pour la configuration générale du module complémentaire IA.
- Une fois le module complémentaire installé, ajoutez des modèles IA. Accédez à l'onglet AI et ouvrez les Paramètres.
- Sélectionnez Modifier les modèles d'IA dans le coin inférieur gauche de la fenêtre et cliquez sur Ajouter.
-
Dans la fenêtre qui s'affiche, sélectionnez Ollama comme fournisseur et définissez l'URL sur
http://localhost:11434.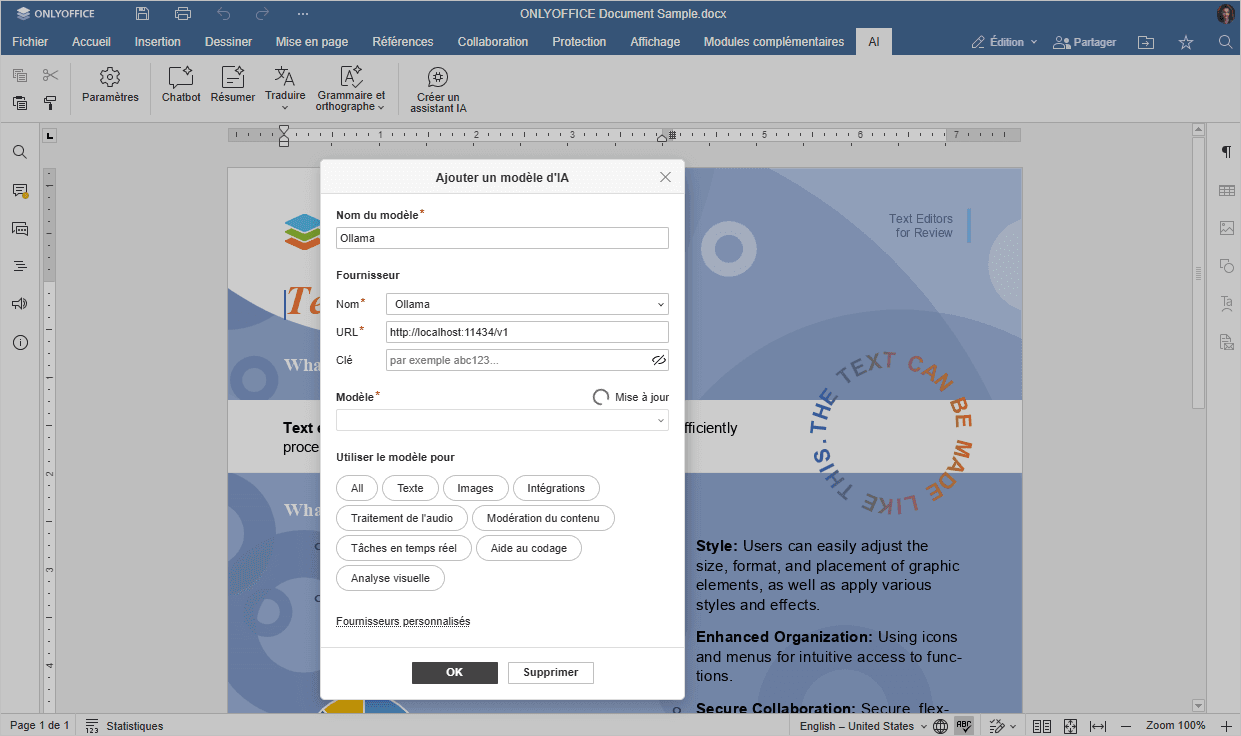
- Sélectionnez le modèle installé (par exemple,
llama3.2:latest) dans la liste déroulante et confirmez. - Parmi les options disponibles, sélectionnez les usages pour lesquels ce modèle sera utilisé : texte, images, intégrations, traitement audio, modération de contenu, tâches en temps réel, aide au codage et analyse visuelle.
- Cliquez sur OK et fermez la fenêtre. Le modèle apparaîtra dans la liste des modèles disponibles.
- Associez différentes tâches à l'IA. Dans la liste déroulante, sélectionnez les modèles IA installés qui exécuteront ces tâches.
- Accédez aux fonctionnalités IA via l'onglet AI ou en sélectionnant du texte et en faisant un clic droit pour ouvrir le menu contextuel.